2020. 7. 17. 21:52ㆍ엑셀/파워피벗 공부
이번 포스팅은 1개의 원본 데이터를 가지고 데이터모델로 생성된 예제를 통해서 Fact테이블(실적)과 Dimension테이블(차원)을 구성해 놓은 모습을 소개합니다.
1. 예제 내용 설명
자주 사용되는 제품/매장/고객/결재 별 매출 실적 데이터를 가지고 구성했습니다.

우선 파워쿼리로 하나의 테이블을 참조하여 제품/매장/고객/결재 차원(Dimension)으로 각각 구성한뒤 다시 인덱스를 만들어서 Fact테이블을 재구성하였습니다.
- fSales 표를 파워쿼리로 생성, 쿼리명은 f매출
- f매출 쿼리를 참조하여 d제품, d매장, d고객유형, d결재방식 쿼리를 각각 만듬
- f매출쿼리와 각 차원(Dimension) 쿼리를 새 쿼리에 병합하여 f매출_인덱스구성 쿼리를 생성
생성된 쿼리들 간의 관계를 "보기>쿼리종속성"를 통해서 확인할 수 있습니다.

최초 원본을 쿼리한 f매출은 로드하지 않고 연결만 만든 상태이고 나머지는 모두 데이터모델로 로드했습니다. 여기서 이렇게 한개를 여러개로 나누어서 사용하면 계속 쿼리만 하고 느려지는 것아닌가 하는 의문이 생겨서 좀 찾아봤습니다.
https://docs.microsoft.com/ko-kr/power-bi/guidance/power-query-referenced-queries<원본>
파워 쿼리의 쿼리 참조 - Power BI
파워 쿼리의 쿼리를 참조하는 방법에 대한 지침입니다.
docs.microsoft.com
쿼리가 두 번째 쿼리를 참조하는 경우 두 번째 쿼리의 단계가 첫 번째 쿼리의 단계와 결합되고 이보다 먼저 실행되는 것과 같습니다.
몇 가지 쿼리를 살펴보겠습니다. Query1은 웹 서비스의 데이터를 원본으로 사용하고 로드는 사용하지 않습니다. Query2, Query3, Query4는 모두 Query1을 참조하고 해당 출력은 데이터 모델에 로드됩니다.

데이터 모델을 새로 고칠 때 파워 쿼리가 Query1 결과를 검색하고 참조된 쿼리에서 다시 사용하는 것으로 가정하는 경우가 많습니다. 이는 잘못된 생각입니다. 실제로 파워 쿼리는 Query2, Query3, Query4를 별도로 실행합니다.
Query2에 Query1 단계가 포함되어 있다고 생각할 수 있습니다. Query3과 Query4도 마찬가지입니다. 다음 다이어그램에서는 쿼리가 실행되는 방식을 보다 명확하게 보여 줍니다.

Query1은 세 번 실행됩니다. 여러 번 실행으로 인해 데이터 새로 고침이 느려지고 데이터 원본에 부정적인 영향을 미칠 수 있습니다.
이렇다 합니다. 하지만 정확한 성능의 비교는 못해봐서 딱히 어떻다고 평하기에는 좀 무리가 있네요. 그러나 저의 체감상으로는 새로고침(데이터 갱신)할때 쿼리의 개수보다는 데이터 용량이 더 속도에 영향을 주는 듯한 느낌을 받습니다.

즉, 테이블이 2개인 1번이 테이블이 1개인 2번의 경우 보다 경험상 더 안정적이였다는 거죠.
물론 항상 그런것은 아니고 주로 데이터가 많을때 (특히 몇개 안되는 id 가 건수만 엄청 많은 경우에 )그리고 name 필드 처럼 설명에 텍스트 값이 길 경우일 수록 그런 경향이 있었던 것으로 생각됩니다. 직접 비교하며 작업하지 않기 때문에 정확하지는 않습니다.
다음은 파워 피벗에 구성된 데이터모델을 살펴보죠. 데이터 모델의 테이블 간의 관계를 나타내는 다이어그램입니다.
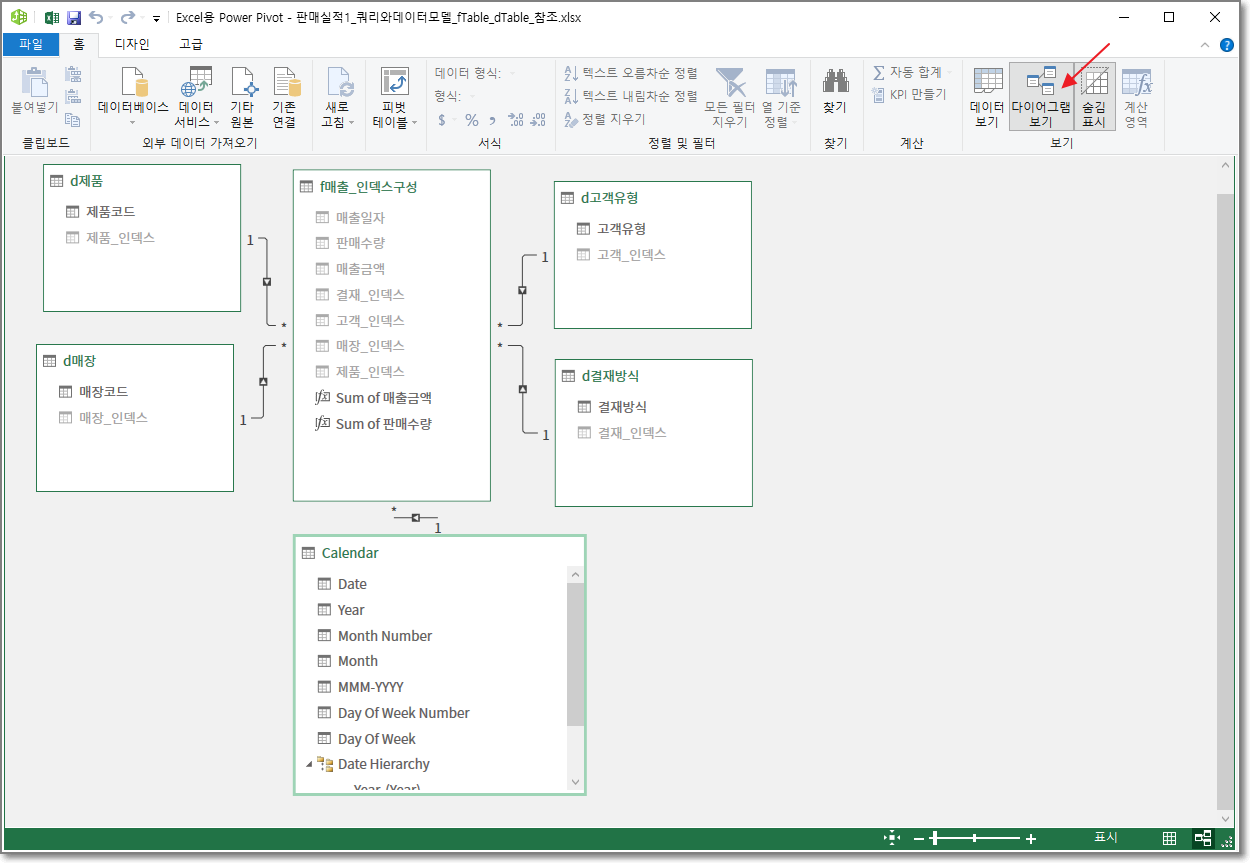
각각의 차원(Dimension) Table과 관계를 구성해놓았습니다. 그리고 파워쿼리에서 인덱스로 만들어놓은 것들은 모두 숨기기 해놓았습니다. 이렇게 되면 엑셀에서 피벗팅 할때 더욱 간결하게 사용이 가능합니다.
마지막으로 엑셀에 구성된 파워피벗 테이블입니다.

피벗테이블에 슬라이서를 달아놓은 상태입니다. 그리고 다음은 필드 목록입니다.
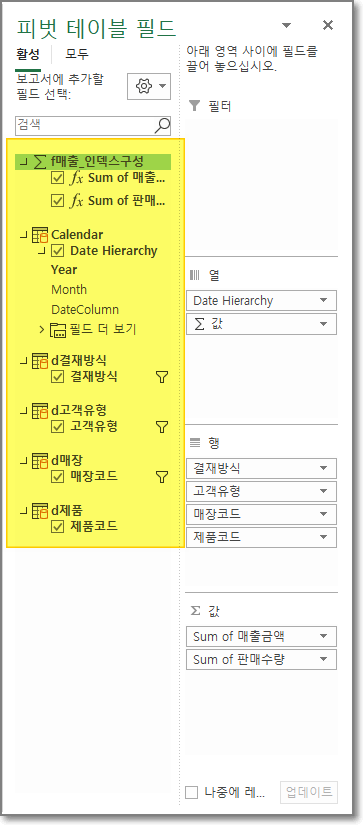
각 차원이 별도의 테이블로 구성되어 있고 값(measure)는 측정값으로만 구성된 항목으로 아예 표시가 테이블이 아닌 측정값으로 표시됩니다.
2. 이렇게 나누어 놓으면 어떤 이점이 있을까?
일단 가독성이 좀 더 좋아지는 것이 있죠. 물론 분석용으로 오늘 한번 사용하는 자료라면 굳이 이렇게 할 이유는 없겠지만 원본데이터를 변경해가며 계속 사용해야 하는 경우에는 좀 신경쓰는 것이 좋을 것이라 생각합니다.
그리도 두번째로는 차원(Dimension)항목들을 다루기 쉽다는 것입니다. 예제 파일을 보면 매장에 대한 정보는 매장 테이블에 매장코드 밖에 없습니다. 여기에 매장명과 위치 등 매장코드를 키로하는 항목들을 추가한다고 했을때 전체 쿼리를 수정하는 것보다 매장쿼리만 손을 보면 되니 훨씬 적은 데이터를 다루며 작업할 수 있게 됩니다.

파워피벗 편집창에서 SWITCH 함수를 통해서 간단하게 매장명을 추가 했습니다.
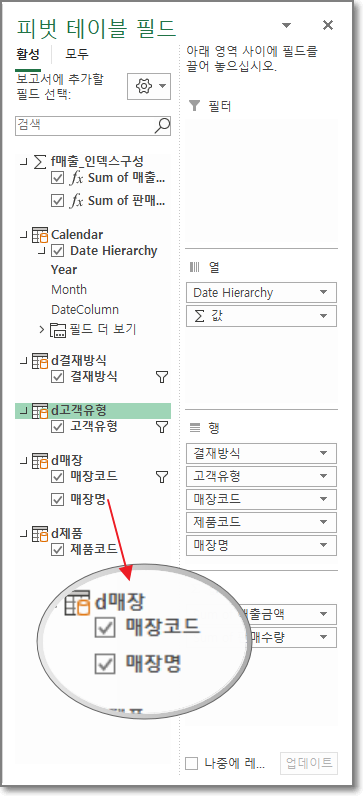
매장명이 추가되어 피벗테이블에서 바로 사용이 가능합니다. 그리고 이 경우에는 원본 데이터의 수정이 없습니다. 즉, 용량을 원본부터 늘려온것이 아니라는 것이죠.
이상으로 하나의 원본 데이터를 가지고 Fact Table과 Dimension Table로 나누어 데이터 모델을 구성하는 예제를 파워쿼리와 파쿼피벗으로 작업한 사례 설명을 마침니다.
'엑셀 > 파워피벗 공부' 카테고리의 다른 글
| CUBESET 함수 멤버 옵션 (0) | 2020.10.16 |
|---|---|
| [파워피벗] 누적측정값으로 일자별 재고 만들기 (0) | 2020.10.15 |
| [파워피벗] 데이터모델 구성할때 테이블 정리 Tip (0) | 2020.07.17 |
| [파워피벗] DAX 함수- CALCULATE (0) | 2020.06.18 |
| [파워피벗 공부] 계획 대비 실적 차이분 예제 (0) | 2020.06.15 |